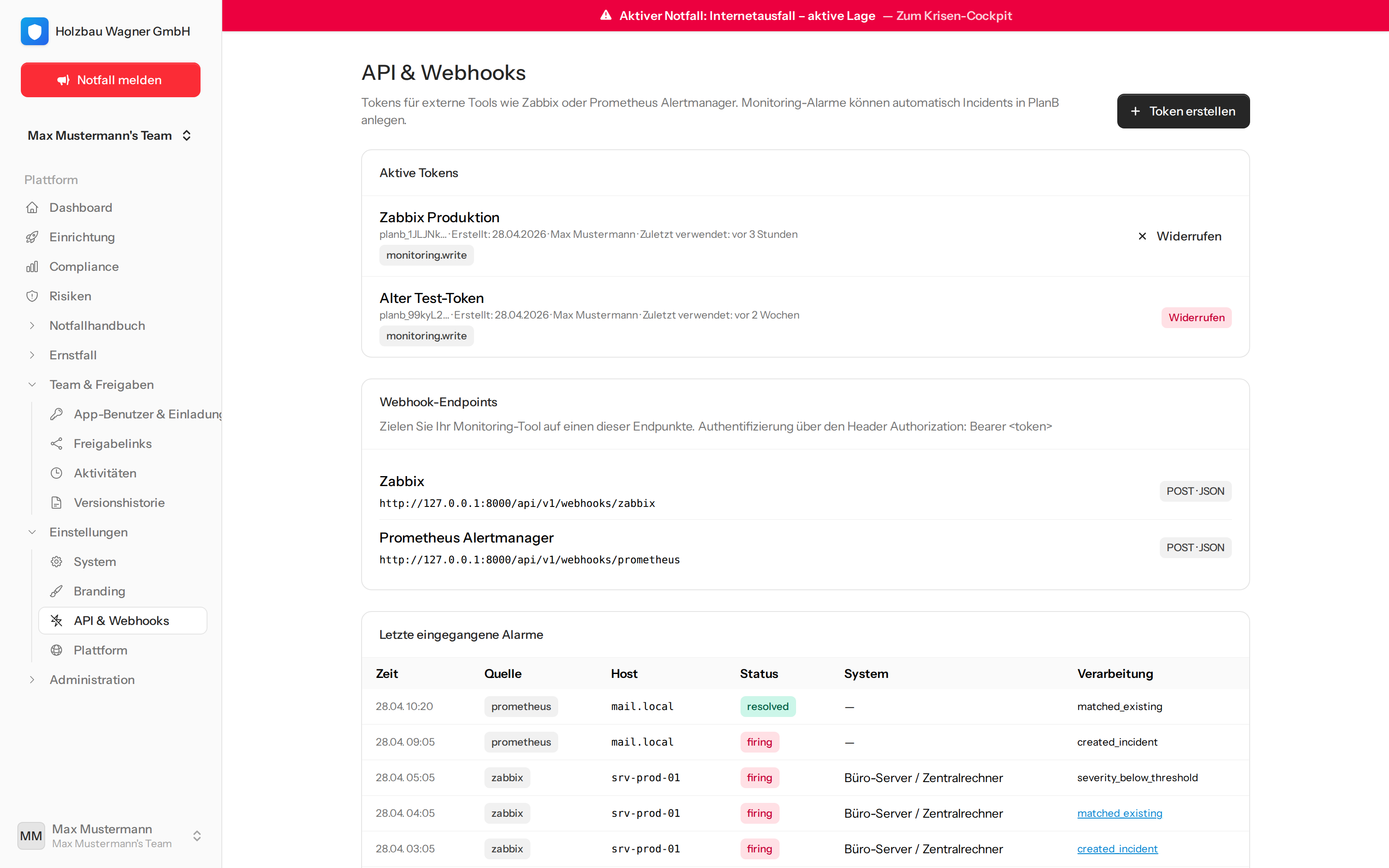
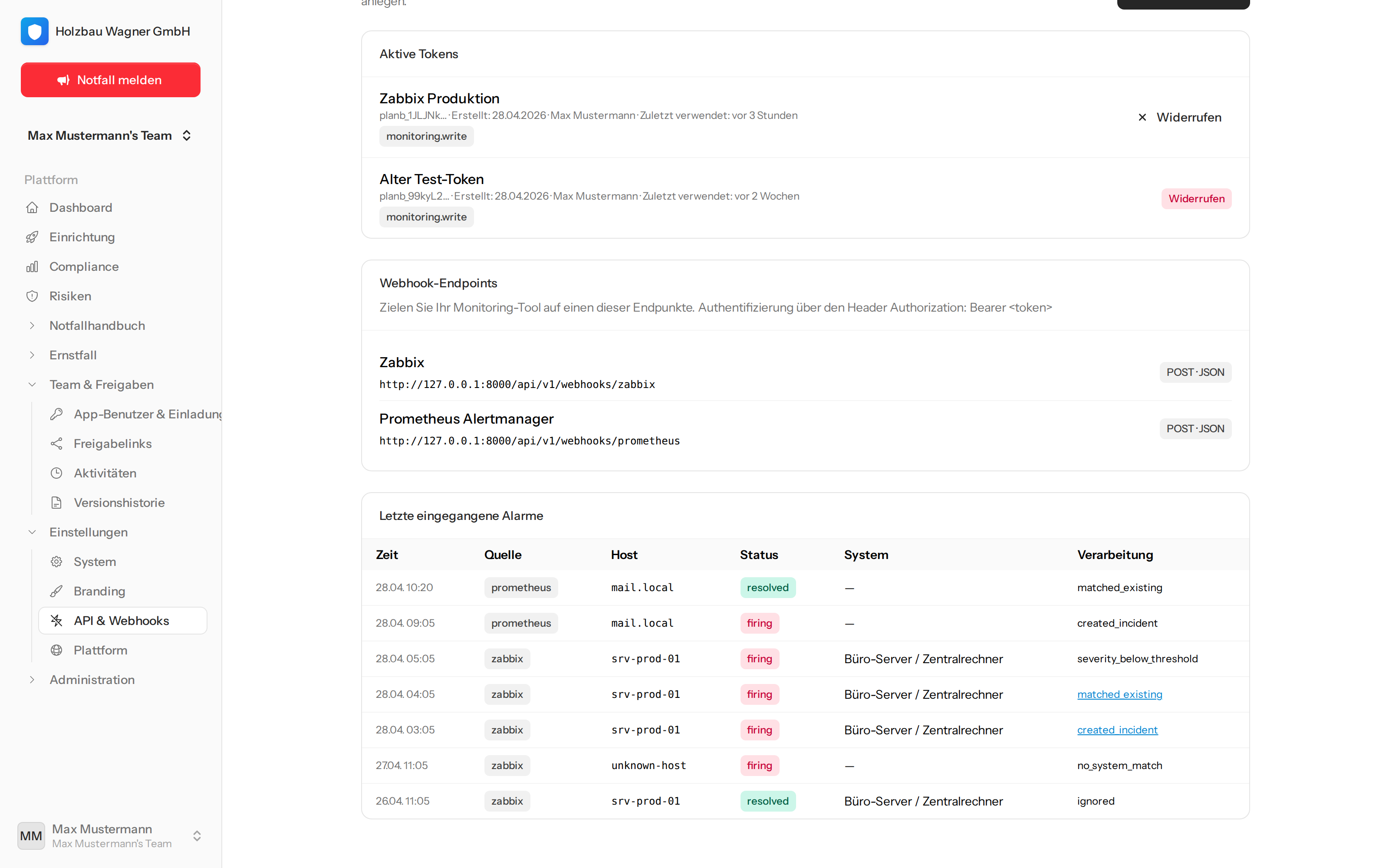
In der Anwendung
So sieht das im laufenden Betrieb aus.
Eingehende Alarme werden je nach Severity, Host-Mapping und Status entweder zu einem Incident eskaliert, an einen offenen Incident angehängt, oder als Information geloggt — das vollständige Verarbeitungs-Log ist jederzeit einsehbar.